KITTI







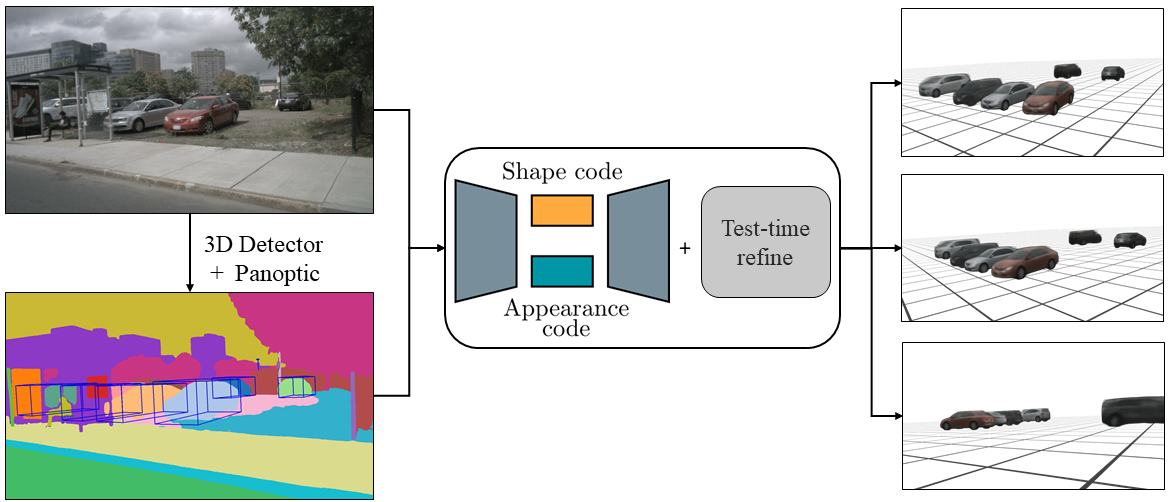
We introduce AutoRF – a new approach for learning neural 3D object representations where each object in the training set is observed by only a single view.
This setting is in stark contrast to the majority of existing works that leverage multiple views of the same object, employ explicit priors during training, or require pixel-perfect annotations. To address this challenging setting, we propose to learn a normalized, object-centric representation whose embedding describes and disentangles shape, appearance, and pose.
Each encoding provides well-generalizable, compact information about the object of interest, which is decoded in a single-shot into a new target view, thus enabling novel view synthesis.
We further improve the reconstruction quality by optimizing shape and appearance codes at test time by fitting the representation tightly to the input image.
In a series of experiments, we show that our method generalizes well to unseen objects, even across different datasets of challenging real-world street scenes such as nuScenes, KITTI, and Mapillary Metropolis.
AutoRF naturally disentangles object shape, appearance and pose. This allows to control each property individually while freely moving the camera leading to the first ever implicitly reverse-parked car.
Even on unseen datasets with highly different camera properties, light conditions and scene compositions, AutoRF can synthesis reasonable scene representations.


For more work on similar tasks, please check out
Common Objects in 3D: Large-Scale Learning and Evaluation of Real-life 3D Category Reconstruction introduces a new dataset for training on real 3d-annotated category-centric data.
NeROIC: Neural Object Capture and Rendering from Online Image Collections, presents another approach for geometry and material estimation by generalizing from large-scale object-centric data.
A similar disentanglement of shape and appearance can be found in CodeNeRF: Disentangled Neural Radiance Fields for Object Categories
There are probably many more by the time you are reading this. Check out Yen-Chen Lin's curated list of NeRF papers.
@inproceedings{mueller2022autorf,
author = {M{\"{u}}ller, Norman and Simonelli, Andrea and Porzi, Lorenzo and Bulò, Samuel Rota and Nie{\ss}ner, Matthias and Kontschieder, Peter}},
title = {AutoRF: Learning 3D Object Radiance Fields from Single View Observations},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022}}